Understanding the Queue
Queues
There are three queues (also sometimes called partitions in the Slurm documentation) on Raj. The default queue is the batch queue. This queue contains all of the general compute nodes, the large memory compute nodes, the massive memory compute nodes and the GPU compute nodes. Jobs submitted to this queue can run on any of these nodes, and the majority of jobs submitted are submitted to this queue. The batch queue has no maximum walltime or maximum amount of resources which can be requested. The second queue is the debug queue. This queue contains the same nodes as the batch queue but gets a boost in priority. However, maximum walltime which can be requested is 30 minutes (or 00:30:00). If a walltime greater than 30 minutes is requested it will be reduced to 30 minutes. The maximum number of resources which can be requested is 64 cores across two nodes (i.e. 64 cores on one node or 32 cores on two nodes). If more resources are requested, the the requests will automatically be reduced to their maximum allowed values. The idea behind this queue is a place for users to easily and quickly troubleshoot a series of small jobs to make sure it runs properly, before launching the actual simulation. This way the user can assure the job won't fail 100 hours into a 300 hour job because of a typo, or that custom compiled code runs small jobs the way it is supposed to before launching a large job.
The final queue is the ai/ml queue. This queue contains the three AI/ML nodes. These nodes are separated from rest of the nodes for two reasons. First is that we do not want jobs which do not specifically require this type of node to be run on these nodes. Second is that at the time of purchasing Raj vendors did not sell eight GPU nodes with AMD processors, but did sell two GPU nodes with AMD processors. Therefore the AI/ML nodes have have Intel processors and the GPU compute nodes have AMD Processors. For this reason different modules need to be loaded depending on whether it is running on the AI/ML nodes or a GPU compute node.
Priorities
When a job is submitted to Slurm it is placed in a queue with other jobs. When that job is run is dependent on three factors. 1) The amount of requested resources. 2) The amount of available resources. 3) The jobs priority. Imagine the following scenario depicted in below. We have a five node cluster running four jobs, with five jobs in the queue.
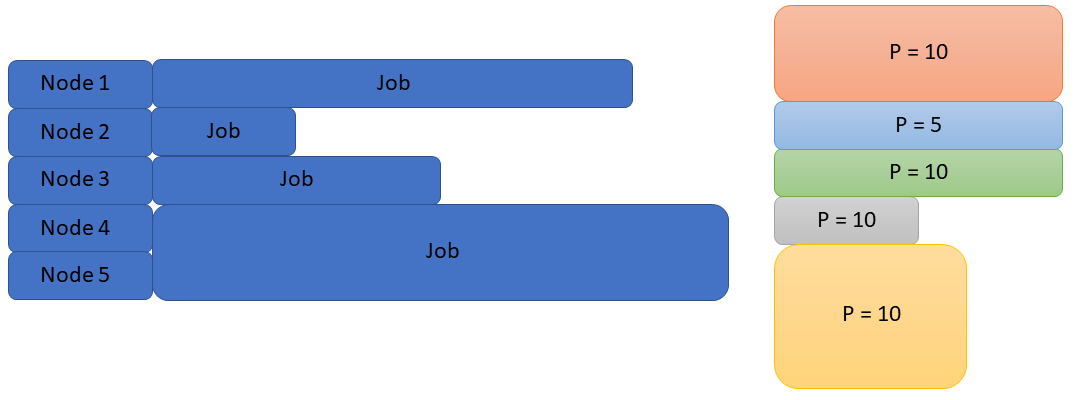
If Slurm used a simple first in first out scheduler (FIFO), there would be significant inefficiencies and idle nodes (see below).
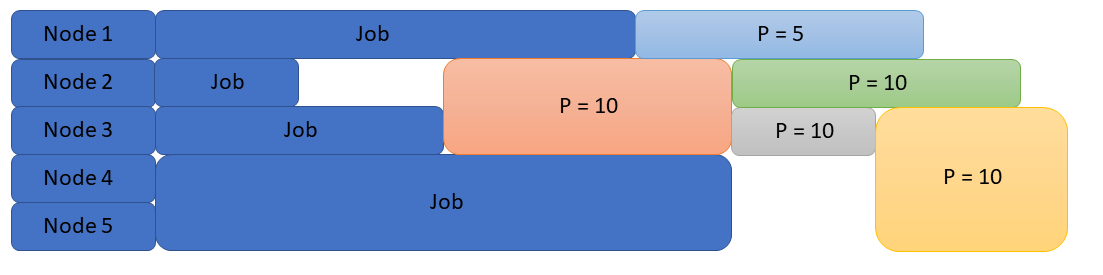
However, using the criteria mentioned above the scheduler can run jobs in a much more efficient manner.
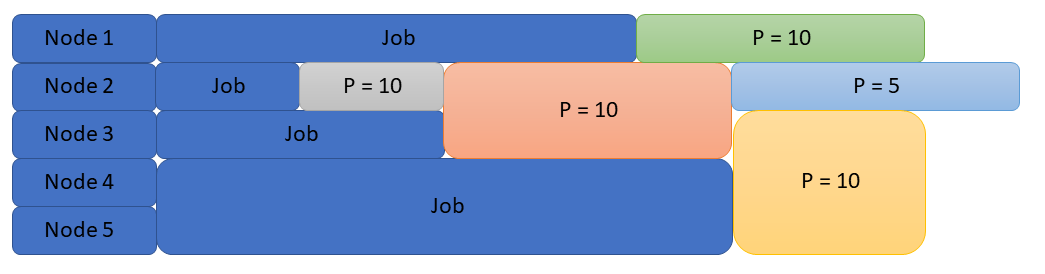
Since it is the first job in the queue, the orange job is still scheduled in the same slot. However, since there is a small gap the gray job fits, it is scheduled to run before the orange job. (This is known as backfilling.) Despite being behind the blue job in the queue, the green job runs next since it has a higher priority. Finally, the gold and the blue jobs start last. Obviously not all scheduling fits together this well and there will naturally be some idle time with jobs in the queue as the scheduler deals with a more complex workload.
Having gone through this example a logical question would be what is job priority and how does it get assigned to jobs? Job priority is affected by four factors. 1) Which queue your job is submitted to. As stated in the section Queues, jobs submitted to the debug queue have a higher priority than jobs submitted to other queues. 2) The number of subsequent jobs submitted by a single user. To more fairly share the resources on Raj, for each job a user currently has in the queue, the next job they submit will receive a modest priority penalty. Thus if a single user submits 6,500 hour long single node jobs, they do not get to monopolize the cluster for the next 100 hours (6,500 node hours/the 65 compute nodes in the batch queue). The 6,500th job this user submits will have a significantly lower priority than the first job submitted by a different user. 3) The number of resources requested. A job which reqeusts a whole node will have a lower priority than a job which requests a single core. 4) How long the job has been in the queue. As the job ages (stays in the queue longer) it accumulates priority.
This increase in priority pertains to the earlier example where a user submits 6,500 hour long single node jobs. Given the priority penalty, the 6,500th job would never run unless the queue was empty of all other jobs. The accumulation of priority with age allows these 6,500 jobs to be sprinkled in as the priority they accumulate overcomes their initial penalty. For more information on how Slurm calculates job priorities, visit Slurm's webpage on multifactor priorities.
Node and Feature Weights
Node weights are another mechanism Slurm uses to assign jobs to specific nodes. The batch queue has multiple different kinds of compute nodes (general, large memory, massive memory and GPU). If jobs were assigned randomly to the pool of available nodes, a job which requires 128 cores may be assigned to a GPU compute node. Then when a job which requires 1 GPU and 64 CPUs is submitted it has to wait for a job which does not require GPUs to finish before it can run. To prevent this, Slurm utilizes node weights. For each core, GB of RAM, or GPU a node has it gets a certain weight value. The weight values for each of these features are added up for each node and a final node weight is assigned to each node. Slurm then assigns jobs to a node with the lowest node weight which is capable of running the job. Feature weights and node weights can be seen in tables below.
Feature Weights
| Feature |
per CPU |
per GB of RAM |
per GPU |
| Weight |
10 |
1 |
1000 |
Node Weights
| Node Type |
General |
Large Mem |
Massive Mem |
GPU |
| Weight |
1792 |
2304 |
3328 |
3792 |
Common Slurm Commands
| Command |
Meaning |
| salloc |
Request an interactive job allocation |
| sattach |
Attach to I/O streams of all the tasks running on a Slurm job |
| sbatch |
Submit a batch script to Slurm |
| scancel |
Cancel a job or job step or signal a running job or job step |
| sdiag |
Display scheduling statistics and timing parameters |
| sinfo |
Display node partition (queue) summary information |
| smap |
A curses-based tool for displaying jobs, partitions and reservations |
| sprio |
Display the factors that comprise a job's scheduling priority |
| squeue |
Display the jobs in the scheduling queues, one job per line |
| sreport |
Generate canned reports from job accounting data and machine utilization statistics |
| srun |
Launch one or more tasks of an application across requested resources |
| sshare |
Display the shares and usage for each charge account and user |
| stat |
Display process statistics of a running job step |
| sview |
A graphical tool for displaying jobs, partitions and reservations |
← Running Jobs on Raj with Slurm
