Raj consists of three main components: the nodes (or servers/computers), the storage system and the network. Raj has several classes of nodes including a login node, a management node, general compute nodes, large memory compute nodes, massive memory compute nodes, GPU compute nodes and AI/ML nodes. The login node is a user's primary point of access, where they can login to the cluster, modify scripts and launch jobs. The management node is where all the back-end management happens which keeps the cluster up and performing optimally. The storage nodes are what manage, maintain and facilitate access to, Raj's high performance global parallel file system. Raj uses IBM's General Parallel File System (or GPFS for short) as its parallel file system.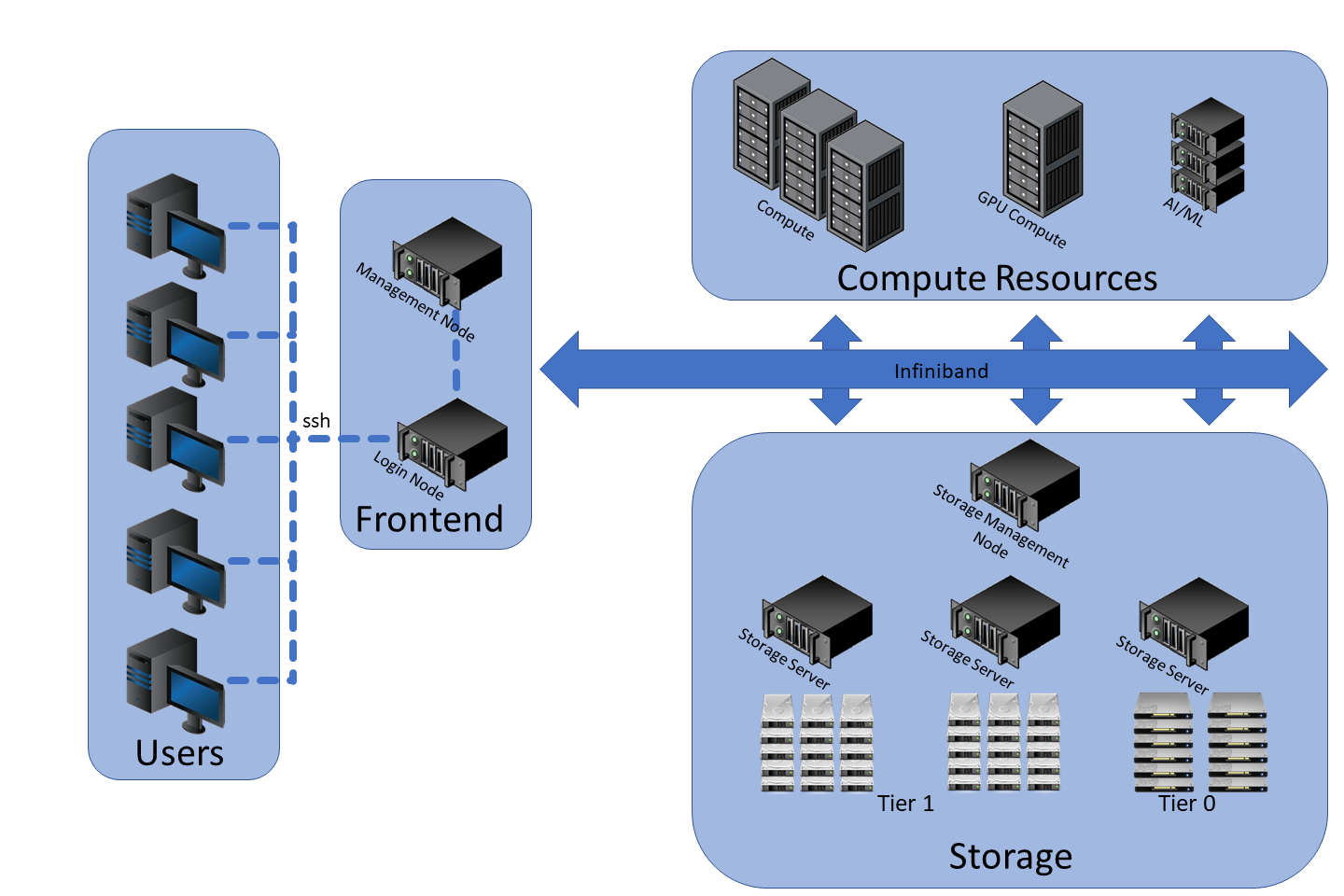
The work horses of the system are Raj's multitude of compute nodes. Specifications for each type of node can be seen in the table below, but an overview of their intended purposes are as follows. The general compute nodes are the backbone of the system providing resources for traditional CPU intensive computations. Over the last several years, the amount of data required to perform, and generated by, simulations has grown considerably. To this end the large and massive memory compute nodes have been included to accommodate those who utilize large (or massive) amounts of RAM in their research.
| Node Type |
Quantity |
Cores |
RAM |
Scratch |
Accelerators |
| General Compute Node |
38 |
128 |
500GB |
1.92TB |
None |
| Large Memory Compute Node |
8 |
128 |
1TB |
1.92TB |
None |
| Massive Memory Compute Node |
3 |
128 |
2TB |
1.92TB |
None |
| GPU Compute Node |
12 |
128 |
500GB |
1.92TB |
NVIDIA Tesla v100 x2 |
| AI/ML Node |
3 |
36 |
768GB |
3.8TB |
NVIDIA Tesla v100 x8 |
The GPU compute nodes have two intended purposes. Many simulation, analysis and data pre/post processing jobs can be accelerated using GPUs. These types of jobs often use CPUs to do a majority of their work, with specific tasks being offloaded to a GPU accelerator. Additionally, many traditional forms of machine learning (ML) and artificial intelligence (AI) algorithms can run optimally on one or two GPUs, so these types of jobs can also be run on the GPU compute nodes. However, some of the more recent forms of AI, specifically deep learning, is significantly more GPU intensive. To this end Raj is equipped with a handful of nodes specifically tailored for this type of job.
Raj has three tiers of storage, two tiers of storage on the global parallel file system, as well as local storage on each compute node. The local storage consists of a single 1.92TB SSD drive on each of the compute nodes and 30TB of NVMe SSD storage on the AI/ML nodes. This tier is used as place to temporarily create files which are generated throughout the course of a job. Files created on the local storage of one compute node cannot be seen by other compute nodes.
The global file system consists of 123TB of NVMe SSD storage (tier 0) and 1.2PB of HDD storage (tier 1). Both of these tiers run IBM's GPFS and are presented to the compute nodes as a single unified namespace. Files written to this filesystem by one compute node can be seen by other compute nodes. Having two tiers allows Raj to leverage the high performance of the NVMe tier, while the HDD tier provides capacity. Newly created files, and files which have recently been read or written to, reside on tier 0. Files which have not been interacted with in some time are migrated to tier 1. Because GPFS has a single namespace the location of the file within the directory tree does not change even if its location on the physical drives (i.e. tier 0 vs tier 1) has changed. For example, a file at /mmfs1/home/user/file can still be found at /mmfs1/home/user/file even if it has migrated tiers. Files which have been migrated to tier 1 can be migrated back to tier 0 if they become actively used again.
Finally, on the network side, the login node is connected the internet and the management node via two 10GB ethernet connections. The login, management and the compute nodes are connected to each other and to the global file system via a 100GB infiniband network. The compute nodes do not have access to the internet, so jobs which incorporate things like wget or curl will not function.
